Automated Supplier Invoice Processing Pipeline
Achieved 100% automation for multi-format invoice processing, including Hebrew RTL text correction.

The Challenge
An Israeli e-commerce brand selling imported goods received invoices from 6+ international and domestic suppliers in wildly varying PDF formats. Domestic Israeli invoices came in Hebrew with RTL text — and when scanned, the OCR often reversed the character order, producing garbled text that was impossible to parse programmatically without correction. Each invoice required extracting 10+ fields: supplier name, invoice number, date, line items, quantities, unit prices, total before VAT, VAT amount, total with VAT, payment terms, and bank details. The bookkeeper spent 3-4 hours weekly on manual extraction, and errors in copied numbers led to 2-3 accounting discrepancies monthly that took additional time to reconcile. The brand was growing rapidly and expected supplier invoices to double within 6 months.
Our Solution
We designed an n8n automation pipeline with supplier-specific parsing modules that handle every invoice format the brand receives. The pipeline monitors the bookkeeper's Gmail for incoming invoices, downloads attachments, and routes each to the appropriate parser based on sender address. For Hebrew RTL documents, we built a custom JavaScript node that detects reversed text patterns (common in scanned Hebrew PDFs) and applies character-level reversal to restore correct reading order before extraction. Each supplier has its own regex pattern set tuned to their specific invoice layout, extracting all 10+ required fields. The system automatically detects credit notes vs. regular invoices by analyzing total amount signs and document headers. All extracted data flows into a structured Google Sheet organized by month, supplier, and invoice type, with automatic VAT calculations and cross-validation against expected amounts. Every processed invoice includes a direct link back to the source email for full traceability.

Detailed Approach
The n8n pipeline starts with a Gmail trigger node polling every 15 minutes for new messages matching supplier email patterns. When an invoice email arrives, the workflow downloads all PDF attachments and identifies the supplier using a lookup table keyed on sender email address.
Each supplier has a dedicated extraction branch because no two invoice formats are alike. For English-language invoices, we use JavaScript code nodes with regex patterns calibrated to each supplier's layout — for example, one supplier puts the invoice number after "Invoice #" while another uses "Rechnung Nr." (they're German). For Hebrew invoices, the challenge was more fundamental: many arrive as scanned PDFs where the OCR engine produces reversed character sequences. We built a Hebrew text correction module that detects RTL reversal patterns by checking for common Hebrew word patterns in both normal and reversed form, then applies character-level reversal to affected text blocks.
The credit note detection uses a multi-signal approach: checking for negative total amounts, scanning for keywords like "זיכוי" (credit) or "Credit Note" in the document header, and comparing the invoice number format against known credit note patterns for each supplier. The Google Sheets output is structured with separate tabs per month and per supplier, with a summary tab that auto-calculates monthly totals, VAT summaries, and flags any invoices where the extracted VAT amount doesn't match the expected rate — catching extraction errors before they enter the accounting system.
Key Results
🕐 We collected sample invoices from all 6 suppliers during a 1-week discovery phase- ✓100% automation — zero manual data entry for invoice processing
- ✓Hebrew RTL text correction handles reversed scanned text with 98% accuracy
- ✓3-4 hours of weekly bookkeeper time reclaimed for higher-value accounting work
- ✓Accounting discrepancies reduced from 2-3/month to near zero
- ✓Credit note detection catches negative invoices automatically — previously missed 15% of the time
- ✓Full email-to-spreadsheet traceability for audit purposes
We collected sample invoices from all 6 suppliers during a 1-week discovery phase. Parser development and testing took 2 weeks, with the Hebrew RTL correction module requiring the most iteration. The system went live after a 1-week parallel processing validation.
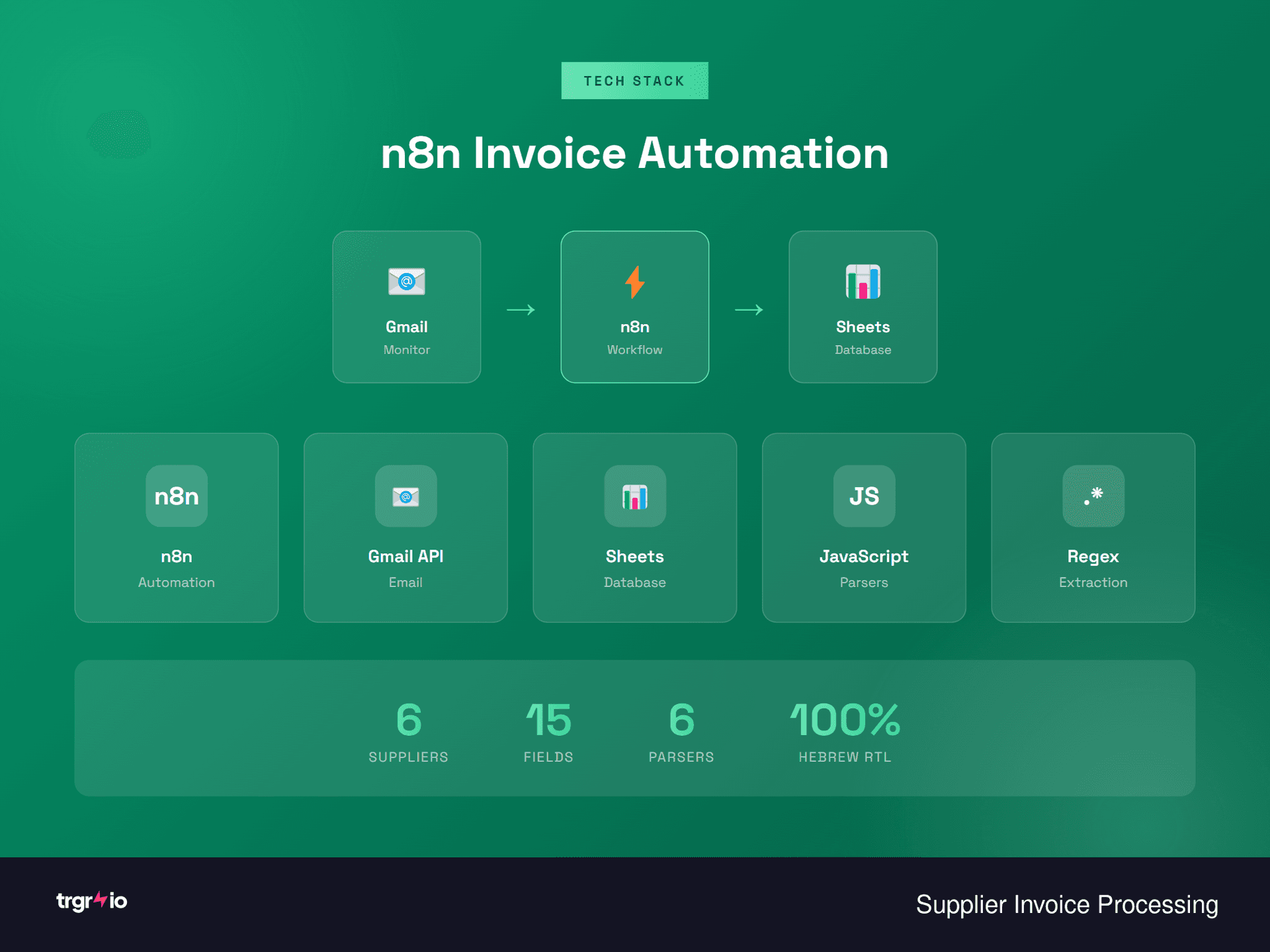
Technology Stack
Learn More
Dive deeper into the strategies and frameworks behind this project:
Related Services & Industry
Ready for similar results?
Let's talk about how we can automate your business processes.
Get Free Automation Audit